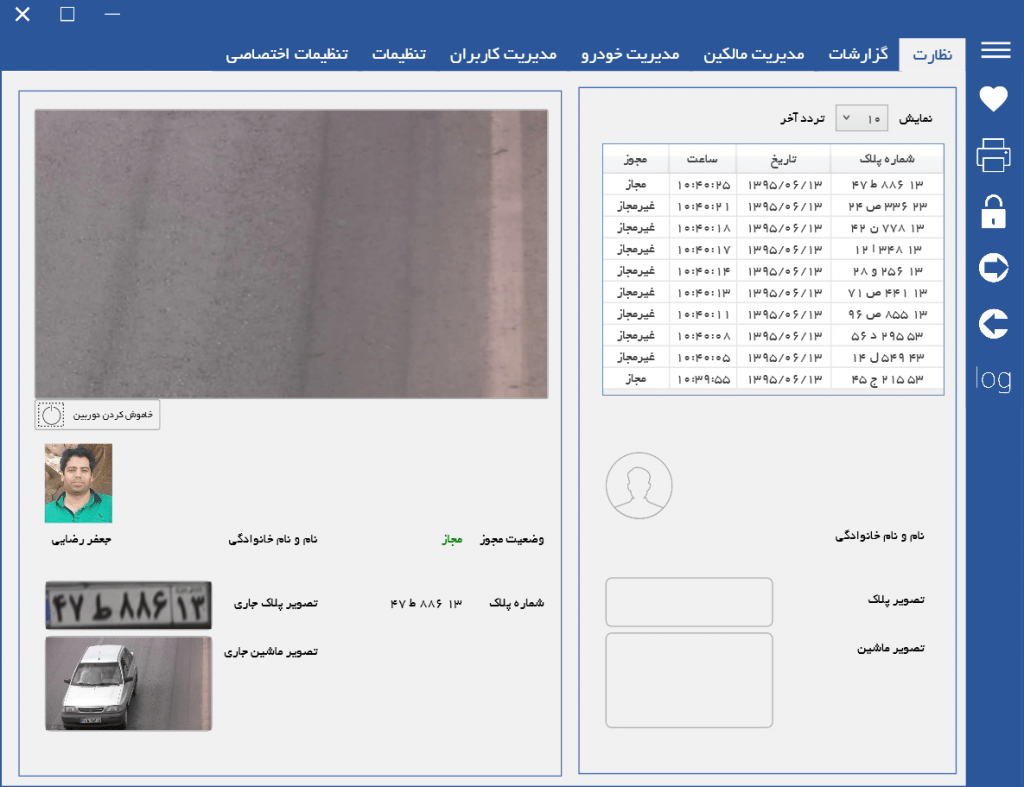
ضرورت پلاکخوانی هوشمند
سامانه های کنترل تردد روز به روز در جهت افزایش رضایتمندی مراجعین، کاهش زمان توقف و بهبود امنیت، ارتقاء پیدا می کنند. پلاکخوانی هوشمند، یکی از ماژولهای اصلی سامانه های مدیریت تردد نوین است. اولین بار در سال ۱۳۸۵ پروژه تشخیص پلاک را برای یک شرکت نیمه دولتی (نرم افزاری-سخت افزاری) انجام دادم. آن زمان پلاکها شامل اسامی شهرها هم بودند که بیش از ۱۶۰ شهر را شامل می شد. این پروژه که چند ماه به طول انجامید برای من حدود ۲ میلیون تومان درآمد داشت اما همان زمان شرکت مزبور هر نسخه اش را به همراه دوربین با قیمت ۵ میلیون تومان می فروخت…
رشد پروژه پلاک خوان
این پروژه تا اوایل سال ۱۳۹۱ مسکوت ماند تا اینکه به تقاضای یک شرکت دیگر، پروژه ای برای تشخیص پلاکهای جدید شروع کردم. هر چند این پروژه چندان درآمدی در آن سال نداشت، اما با انتشار آن در سایت http://farsiocr.ir به تدریج مشتریانی پیدا شد و این شد که کتابخانه تشخیص پلاک ایرانی با نام ساتپا (سامانه تشخیص پلاک ایرانی) یکی از محصولات پرفروش سایتم شد. شرکتهایی بسیار بزرگی در حوزه کنترل تردد برای خرید کتابخانه به من مراجعه کردند. شرکتهایی که هر کدامشان پروژه های بسیاری در حوزه مدیریت تردد خودرو در کشور داشتند و دارند.
الحمدلله این کتابخانه پلاکخوان مرتب به روز شد و الان نسخه ۷٫۲۵ آن در سایت منتشر شده است. متاسفانه به دلیل فضای نامطلوب نرم افزاری و عدم تعهد برخی فعالان این حوزه، گهگاهی می بینم کتابخانه پلاک خوان ما با نامهای دیگر در فضای اینترنت تبلیغ شده و بعضا به فروش می رسد.
این شد که به اتفاق همکاران شرکت شهاب، تصمیم گرفتیم در یک اقدام منسجم صفحه اول گوگل را برای جستجوی عبارات پلاکخوان، پلاک خوان، تشخیص پلاک، مدیریت پارکینگ و کنترل تردد به تسخیر خودمان درآوریم و این پست تبلیغاتی، یکی از این اقدامات است!
برای آگاهی از امکانات کتابخانه پلاکخوان ساتپا و سامانه مدیریت تردد آی پلاک، ادامه مطلب را بخوانید: